Оптимизация обработки слабоструктурированных данных
Слабоструктурированные типы данных, такие как MAP, STRUCT, JSON и ARRAY, широко применяются в разных сценариях благодаря своей гибкости. Анализировать их сложнее, чем структурированные данные, но эти проблемы легко решаются с помощью генерируемых столбцов.
Генерируемые столбцы (Generated Columns) в Селене – это специальные столбцы, значения которых автоматически вычисляются на основе выражений, использующих другие столбцы той же таблицы. Значения столбцов генерируются на основе указанного выражения при вставке или обновлении данных.
Существует два типа генерируемых столбцов:
Генерируемые столбцы используются для:
Ограничения:
В этой статье мы рассмотрим, почему так трудно ускорить анализ слабоструктурированных данных и как генерируемые столбцы позволяют экономить время.
Сложности с анализом слабоструктурированных данных
При обработке слабоструктурированных данных возникают разные проблемы, и две главные из них — сложности с извлечением и ресурсоемкие вычисления.
Для решения этих проблем можно использовать генерируемые столбцы.
Генерируемые столбцы в слабоструктурированных данных
Генерируемые столбцы помогают эффективно решать проблемы с обработкой слабоструктурированных данных. Они содержат значения, автоматически вычисленные на основе заданных выражений. Вот как это работает.
Как генерируемые столбцы ускоряют обработку слабоструктурированных данных
Для слабоструктурированных данных можно на этапе загрузки рассчитать сложные выражения и сохранить значения в генерируемых столбцах, как показано на схеме ниже:
Слабоструктурированные типы данных, такие как MAP, STRUCT, JSON и ARRAY, широко применяются в разных сценариях благодаря своей гибкости. Анализировать их сложнее, чем структурированные данные, но эти проблемы легко решаются с помощью генерируемых столбцов.
Генерируемые столбцы (Generated Columns) в Селене – это специальные столбцы, значения которых автоматически вычисляются на основе выражений, использующих другие столбцы той же таблицы. Значения столбцов генерируются на основе указанного выражения при вставке или обновлении данных.
Существует два типа генерируемых столбцов:
- VIRTUAL (по умолчанию) - значения вычисляются "на лету" при чтении
- STORED - значения вычисляются при записи и физически сохраняются
Генерируемые столбцы используются для:
- Упрощения запросов (можно ссылаться на вычисляемый столбец вместо сложного выражения)
- Оптимизация производительности (особенно для STORED столбцов)
- Поддержки индексов на вычисляемых столбцах
Ограничения:
- Выражение может ссылаться только на другие столбцы той же таблицы
- Не могут содержать подзапросы или агрегатные функции
- Не могут быть изменены напрямую (только через изменение исходных столбцов)
- Генерируемые столбцы особенно полезны для часто используемых вычислений или для создания материализованных представлений на уровне столбцов.
В этой статье мы рассмотрим, почему так трудно ускорить анализ слабоструктурированных данных и как генерируемые столбцы позволяют экономить время.
Сложности с анализом слабоструктурированных данных
При обработке слабоструктурированных данных возникают разные проблемы, и две главные из них — сложности с извлечением и ресурсоемкие вычисления.
- Сложности с извлечением. В сложных типах данных (MAP, STRUCT, JSON) поля часто хранятся единым блоком, который приходится извлекать целиком, чтобы проанализировать конкретное поле. Это негативно сказывается на скорости передачи данных.
- Ресурсоемкие вычисления. Для агрегирования, сортировки и других OLAP-операций напрямую со слабоструктурированными данными требуются значительные вычислительные ресурсы, что замедляет обработку и снижает масштабируемость.
Для решения этих проблем можно использовать генерируемые столбцы.
Генерируемые столбцы в слабоструктурированных данных
Генерируемые столбцы помогают эффективно решать проблемы с обработкой слабоструктурированных данных. Они содержат значения, автоматически вычисленные на основе заданных выражений. Вот как это работает.
Как генерируемые столбцы ускоряют обработку слабоструктурированных данных
Для слабоструктурированных данных можно на этапе загрузки рассчитать сложные выражения и сохранить значения в генерируемых столбцах, как показано на схеме ниже:
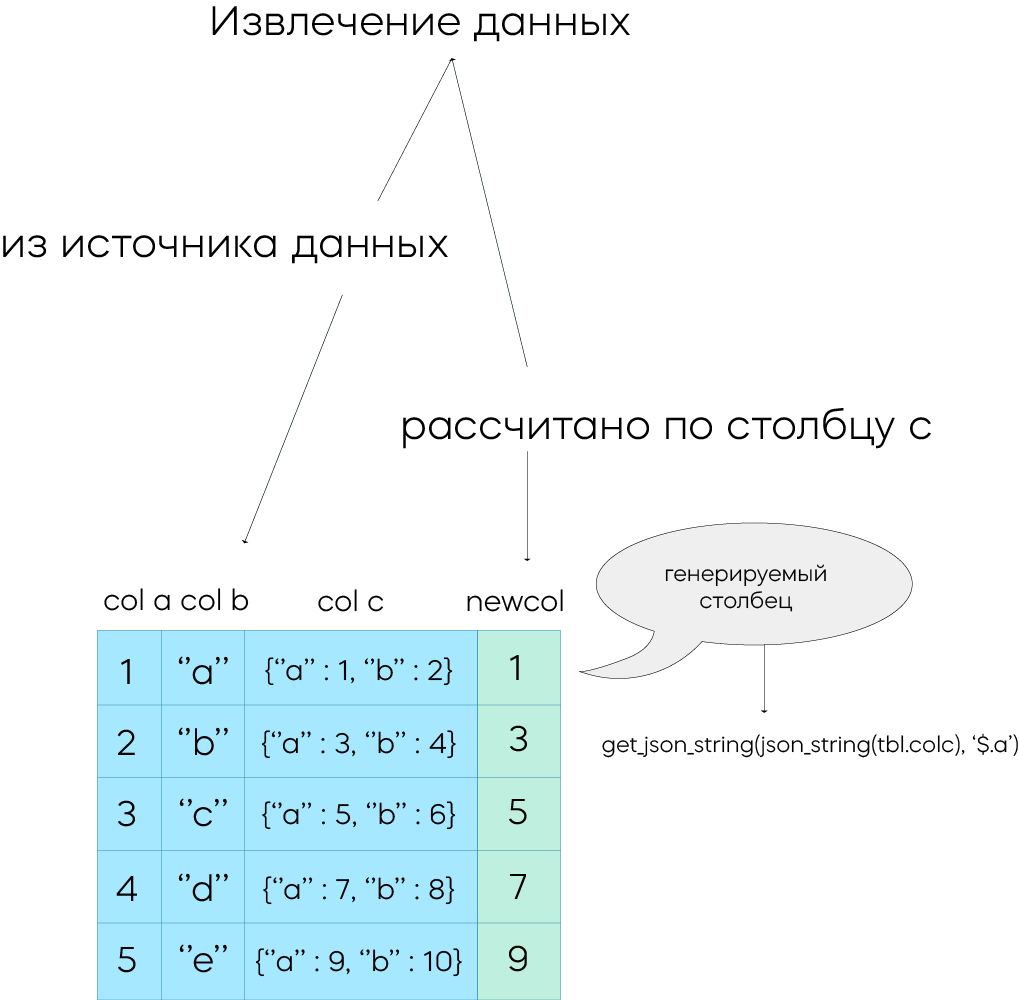
Этот подход не только ускоряет извлечение данных во время запросов, но и снижает вычислительные затраты, позволяя быстрее выполнять запросы и решая большинство проблем, которые возникают при работе со слабоструктурированными данными.
Пример реализации генерируемых столбцов
Рассмотрим возможности генерируемых столбцов на примере Селены, использующую StarRocks в качестве механизма хранения данных. Селена – это высокопроизводительная база данных на основе OLAP, способная обрабатывать большой объемов запросов с задержкой менее одной секунды. Генерируемые столбцы представлены в версии 1.3. Этот инструмент не требует длительной настройки и предоставляет широкие возможности для простой и быстрой работы. Одна из ключевых функций Селены – автоматическое переписывание запросов под генерируемые столбцы.
Переписывание запросов под генерируемые столбцы
Для доступа к результатам выражений, хранящимся в генерируемых столбцах, в SQL-запросе необходимо указать имя столбца. Требуется приложить довольно много усилий, чтобы отредактировать существующие SQL-запросы вручную.
К счастью, Селена поддерживает автоматическое переписывание запросов. На этапе составления плана запросов SQL-оптимизатор анализирует все выражения в запросе и переписывает те, которые привязаны к генерируемым столбцам.
Например, если запрос должен извлечь поле 'a' из столбца 'colc', стандартный запрос выглядел бы так:
Пример реализации генерируемых столбцов
Рассмотрим возможности генерируемых столбцов на примере Селены, использующую StarRocks в качестве механизма хранения данных. Селена – это высокопроизводительная база данных на основе OLAP, способная обрабатывать большой объемов запросов с задержкой менее одной секунды. Генерируемые столбцы представлены в версии 1.3. Этот инструмент не требует длительной настройки и предоставляет широкие возможности для простой и быстрой работы. Одна из ключевых функций Селены – автоматическое переписывание запросов под генерируемые столбцы.
Переписывание запросов под генерируемые столбцы
Для доступа к результатам выражений, хранящимся в генерируемых столбцах, в SQL-запросе необходимо указать имя столбца. Требуется приложить довольно много усилий, чтобы отредактировать существующие SQL-запросы вручную.
К счастью, Селена поддерживает автоматическое переписывание запросов. На этапе составления плана запросов SQL-оптимизатор анализирует все выражения в запросе и переписывает те, которые привязаны к генерируемым столбцам.
Например, если запрос должен извлечь поле 'a' из столбца 'colc', стандартный запрос выглядел бы так:
SELECT get_json_string(json_string(tbl.colc), '$.a') FROM tbl;Процесс выглядел бы следующим образом:
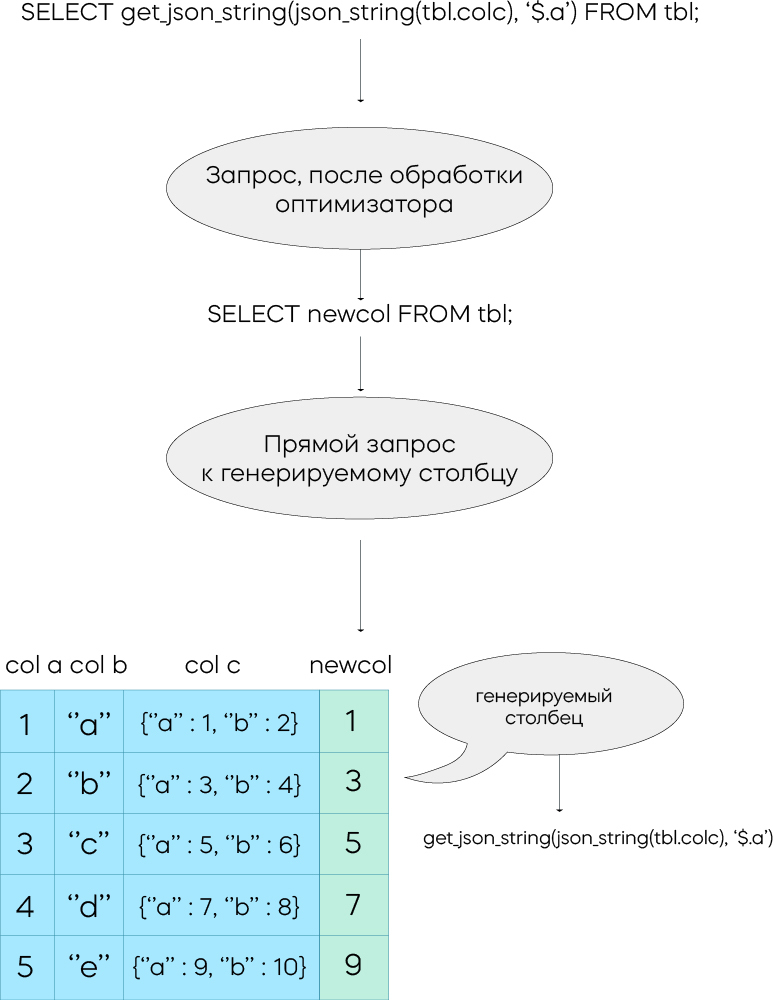
Оптимизатор автоматически перепишет запрос, чтобы значение извлекалось из генерируемого столбца, а результат возвращался гораздо быстрее.
Эффективное добавление генерируемых столбцов
Генерируемые столбцы могут добавляться в существующие таблицы на регулярной основе. Например, если обнаруживается проблема с производительностью при вычислении определенного выражения, можно добавить генерируемый столбец и ускорить конкретный запрос.
Эффективное добавление генерируемых столбцов
Генерируемые столбцы могут добавляться в существующие таблицы на регулярной основе. Например, если обнаруживается проблема с производительностью при вычислении определенного выражения, можно добавить генерируемый столбец и ускорить конкретный запрос.
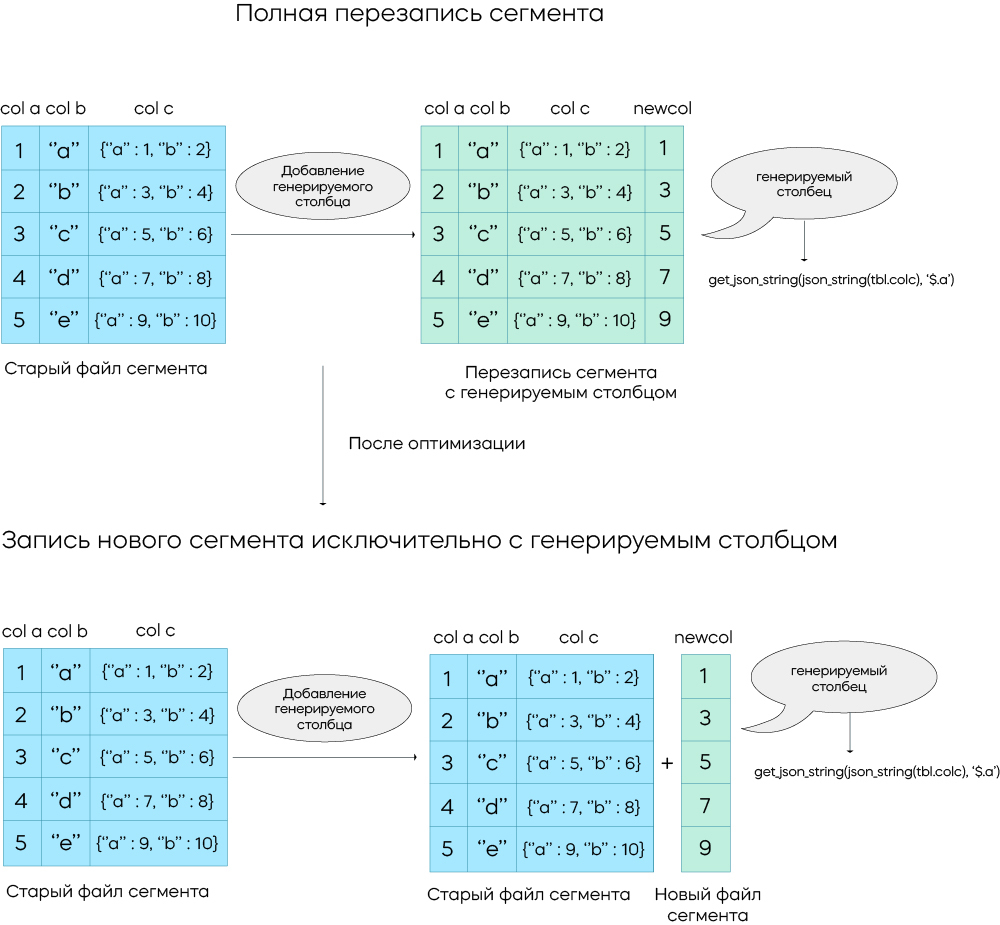
В таких случаях Селена не перезаписывает существующие физические файлы, чтобы добавить в таблицы генерируемые столбцы. Обновляются только метаданные: в трафик при чтении входят только столбцы, используемые в выражении генерируемого столбца, а в трафик при записи – только результаты вычисления выражения для этого столбца. Такой подход значительно повышает эффективность операций ввода-вывода при изменениях схемы, позволяя добавлять генерируемые столбцы по необходимости для ускорения запросов.
Тестирование производительности при использовании генерируемых столбцов
Чтобы проверить, на сколько генерируемые столбцы в слабоструктурированных данных ускоряют выполнение запросов, мы провели несколько тестов. Ниже описана их методология, запросы и результаты, чтобы вы могли повторить тесты при желании.
Среда
Селена v 1.3, 1 фронтед-узел и 1 бэкенд-узел, 104 виртуальных ядра, 376 ГБ памяти
Создание таблицы
Тестирование производительности при использовании генерируемых столбцов
Чтобы проверить, на сколько генерируемые столбцы в слабоструктурированных данных ускоряют выполнение запросов, мы провели несколько тестов. Ниже описана их методология, запросы и результаты, чтобы вы могли повторить тесты при желании.
Среда
Селена v 1.3, 1 фронтед-узел и 1 бэкенд-узел, 104 виртуальных ядра, 376 ГБ памяти
Создание таблицы
CREATE TABLE `t` (
`id` bigint(20) NOT NULL COMMENT "",
`array_int` ARRAY<int(11)> NOT NULL COMMENT "",
`json_data` json NOT NULL COMMENT "",
`gc_1` double NULL AS array_avg(`test`.`t`.`array_int`) COMMENT "",
`gc_2` ARRAY<int(11)> NULL AS array_sort(`test`.`t`.`array_int`) COMMENT "",
`gc_3` varchar(65533) NULL AS get_json_string(json_string(`test`.`t`.`json_data`), '$.a') COMMENT ""
) ENGINE=OLAP
PRIMARY KEY(`id`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`id`) BUCKETS 48
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "false",
"replicated_storage" = "true",
"compression" = "LZ4"
)Стандартные столбцы:
Запросы
- id: первичный ключ для уникальности.
- array_int: массив целых чисел длиной 10 000, содержащий случайные числа.
- json_data: содержит ключ 'a' с целочисленным значением 1 и ключ 'b' со стройкой из 100 UUID.
Запросы
-- q1
SELECT get_json_string(json_string(json_data), '$.a') FROM A
-- q2
SELECT array_avg(array_int) FROM A;
По результатам тестов можно сделать следующие выводы:
- q1: вложенное поле было извлечено из большого поля JSON с помощью генерируемого столбца, что позволило сократить затраты на передачу данных и увеличить скорость более чем в 4 раза.
- q2: генерируемый столбец для агрегации большого поля ARRAY (расчет среднего значения) не только снизил затраты на ввод-вывод при чтении слабоструктурированных данных, но и значительно сократил потребление ресурсов ЦП на агрегирование ARRAY, что позволило ускорить запрос в сто раз.
Поэкспериментируйте с генерируемыми столбцами
Очевидно, что генерируемые столбцы позволяют ускорить анализ слабоструктурированных данных, сократить передачу данных и снизить потребление ресурсов ЦП при выполнении сложных выражений. В некоторых сценариях запросы выполняются в сто раз быстрее.