I'm available for business trips to other cities for projects lasting a month or longer.

Платформа Data Lakehouse – Селена


Селена — система хранения и обработки данных класса Data Lakehouse Используют…
Переосмысление корпоративных хранилищ и озер данных в новом поколении систем

В реестре российского ПО
- Аналитические платформы и инструменты используют решение для поиска зависимостей и формирования прогнозов.
- Отчётные BI-системы – для построения сводной и детальной отчётности компании, в том числе в реальном времени.
- Команды ML – для доступа к дата-сетам и обучения моделей.
Вебинар о Data Lakehouse!
Регистрируйтесь прямо сейчас
Дискуссия от экспертов и выступление представителя платформы StarRocks!
Хранение структурированных, полуструктурированных и неструктурированных данных



Инструмент для извлечения и анализа больших данных
Единая точка работы со всеми данными, включая федеративные запросы к данным вне Селены
Инструменты взаимодействия с дата-сетами для ML


База хранения векторных данных для ИИ
Для каких задач применяется Селена
Присоединяйтесь!
Наши ближайшие активности
- Российское решение Data Lakehouse - СеленаСКОРО — вебинар, который закроет все вопросы о Data LakehouseЗапросить запись
- Митап с дискуссией и гостем из StarRocksВебинар прошёл, но вы можете ознакомиться с записью. Запросите её на странице!Запросить запись
-
Аналитики программных продуктов: A/B анализ, пользовательская конверсия, когорты и др.
Маркетинговой аналитики: анализ сезонности, спроса и частотности, программы лояльности и др.
Построения хранилища данных для отчётности: управленческой, финансовой, бизнес-аналитики, регуляторной
Налогового мониторинга: предоставление данных для регуляторов с коротким сроком реакции
Взаимодействия с маркетплейсами: быстрое предоставление данных для e-commerce и запросов с коротким сроком реакции
Финансовый скоринг: ведение кредитной истории и информации по клиенту, оценка доходов и надежности клиента, расчет скорингового балла
Селена будет полезна в целях
Сбора данных для различных целей: IoT, CRM, ERP, ТоИР, MES, PLM/PDM, SCADA и др.
Предиктивной аналитики: анализ временных рядов, регрессионный анализ, кластерный, ковариационный анализ
Анализа биржевых сделок: хранение истории цен финансовых инструментов, проведение расчетов по техническому анализу
Контроллинга: анализ себестоимости в производстве и логистике, распределение затрат
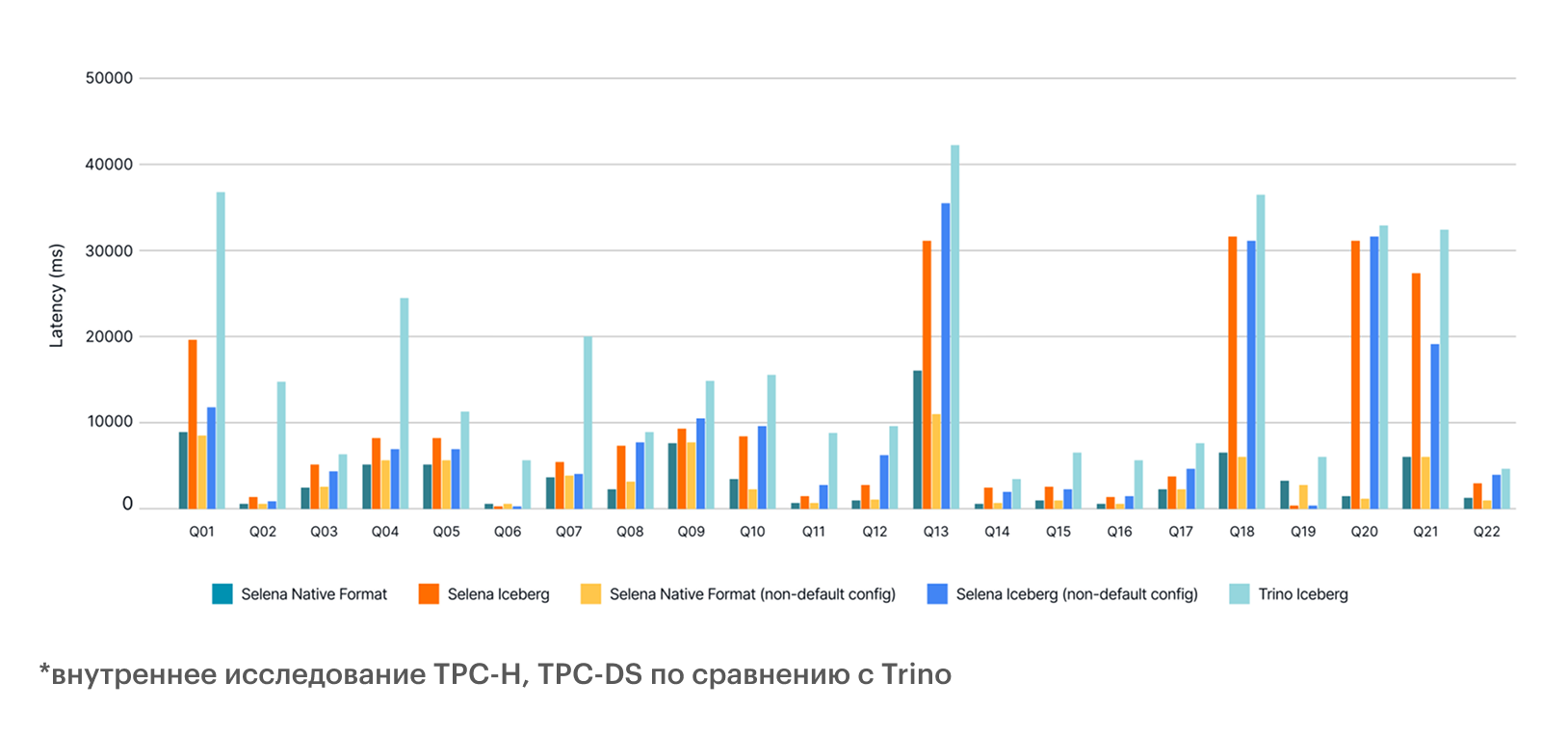
сокращается время на предоставление данных
до
раз
4-х
чем конкуренты по бенчмаркам
В
раза быстрее*
3
снижения дублирования данных
до
20%
оптимизация ТСО
на
20%
сокращение затрат на оборудование
>30%
Почему выбирают Селену

Централизованное управление доступом к данным во всех источниках
Простое администрирование системы и развертывание
Поддержка высоких нагрузок – сотни петабайт и больше
Отказоустойчивость – работа кластера без единой точки отказа
Селена сможет заменить


Data Lake


Форки
Витринные базы


Российские DWH

Западные MPP
Векторные базы

Зарубежные платформы

Основная функциональность решения




Оптимизатор на основе стоимости извлечения данных (Cost-based optimizer)
Кэширование данных
Векторизованный механизм исполнения запросов, оптимизированный для SIMD
Синхронные (SMV) и асинхронные (AMV) материализованные представления
Архитектура с разделением данных


Преимущества Data Lakehouse в выборке и хранении данных:
Наполнение системы данными, в том числе для обеспечения аналитики в реальном времени
Большое число коннекторов для извлечения данных из внешних источников
Интегрированное решение с платформой данных
Встроенный ETL-инструмент:
Визуальное средство для просмотра данных и метаданных
Управление ролями и пользователями
Инструмент для анализа данных при помощи SQL
Управление кластерами: добавление нод, мониторинг
IDE:
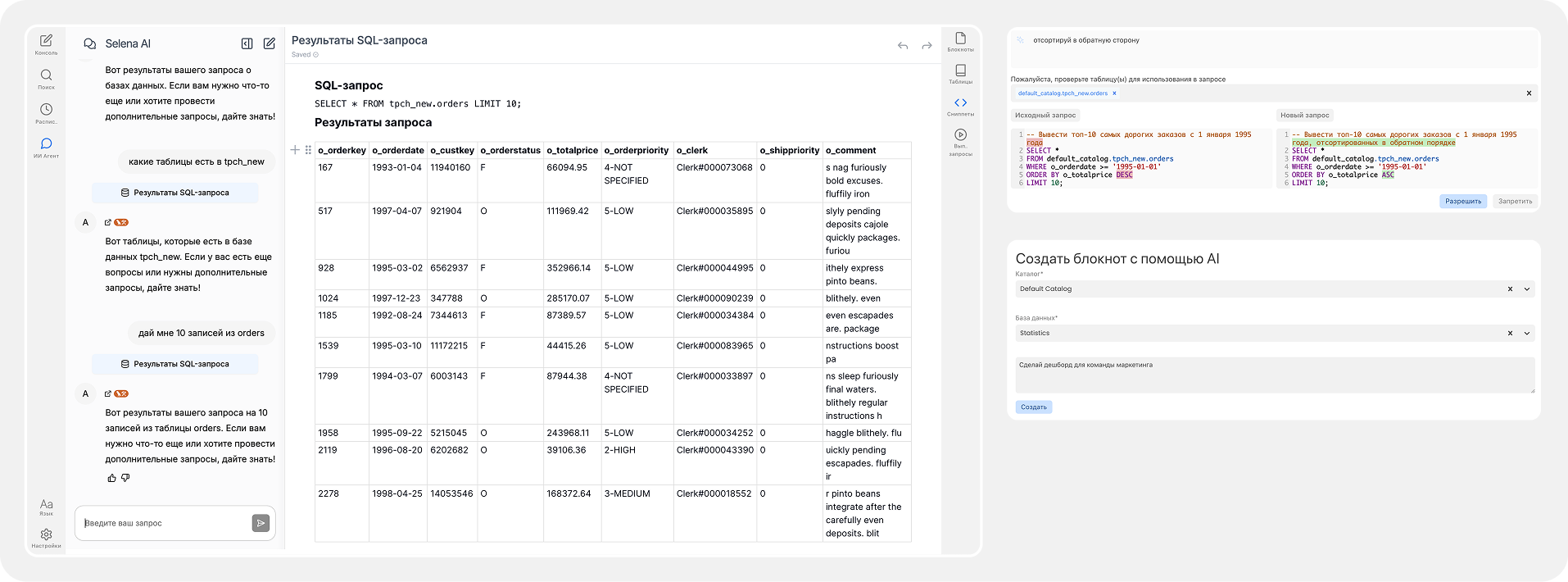
ИИ ассистент (Copilot) – встроен в IDE, является связующим звеном между хранилищем и пользователем: создает новые блокноты, отчеты, запросы
Позволяет вести диалог с хранилищем на естественном языке. Общение в формате привычного чата упрощает доступ к данным без необходимости писать код
Формирует SQL-запросы через описание задачи на русском языке
Объясняет сложные SQL запросы текстом
Выполняет все операции с учетом контекста и текущей роли пользователя
Искусственный интеллект:
Получите дополнительную информацию
о решениях или запросите демо
о решениях или запросите демо
Обратная связь
Поддержка, документация и учебные курсы на русском языке
Регистрация в едином реестре российского ПО №27176 от 19.03.2025
Центры разработки в РФ
Отсутствие валютных рисков – цены в рублях
Документация
Функциональные характеристики
Тариф
Стоимость ПО рассчитывается индивидуально
Документация
Руководство
пользователя
Документация
Информация для установки
Отечественное программное обеспечение

Выбирайте Селену вместо Open Source





Основные этапы проекта:
Разработка бизнес-слоя
Настройка процессов загрузки и улучшения качества данных
Первичная загрузка данных, обеспечение качества, постановка в промышленный режим
Обучение команды клиента
Проектирование целевой архитектуры
Обследование источников данных, ландшафта
Внедрение и поддержка Селены
Обследование источников данных
Установка платформы Селена
Настройка процессов загрузки и улучшения качества данных
Ммиграция данных из существующего хранилища и обеспечение их качества
Тестирование
Проектирование загрузки потоков данных из источников
Основные этапы проекта:
Компания DIS Group, мастер-дистрибьютор Селены, предоставляет полный спектр услуг по внедрению платформы данных. Варианты развертывания и внедрения решения:
Внедрение Data Lakehouse «под ключ»
Результаты:
Вы получите структурированное хранение данных с выстроенными процессами контроля качества и мониторингом загрузки данных. Данные станут легко доступны для использования различными аналитическими инструментами, а также аналитическими моделями. Будет обучена команда клиента по сопровождению и разработке ХД, при необходимости выделены специалисты интегратора для развития системы.
Миграция данных с СУБД, Hadoop и т.д.
Поддержка Селены
Попробуйте Селену в пилотном режиме – вы почувствуете разницу в скорости с первых запросов
1, 2 и 3 линии поддержки



Доступ к обновлениям системы
Регистрация обращений через портал
Несколько уровней поддержки: Премиальный, Премиальный Плюс


Время реакции на критические ошибки – 1 час, 24/7
